Comprendre
DeepSWE: le benchmark qui teste vraiment les agents code
DeepSWE teste les agents code avec des prompts courts et des tâches réalistes. Analyse Kryve du benchmark, des scores et des limites.

DeepSWE est en train de faire parler parce qu'il touche un point sensible : les benchmarks de coding agents racontent parfois une histoire trop propre. Sur beaucoup de leaderboards, les meilleurs modèles semblent très proches. En pratique, quand tu donnes un vrai repo à un agent, avec une demande courte et peu cadrée, l'écart devient beaucoup plus visible.
Le signal important n'est pas seulement "les tâches sont longues". Ce serait trop plat. Le vrai signal, c'est le contraste : DeepSWE donne des prompts plus courts que SWE-Bench Pro, mais demande beaucoup plus de travail logiciel derrière. Autrement dit, l'agent reçoit moins de mode d'emploi, puis doit explorer le codebase, comprendre où intervenir, modifier plusieurs fichiers, vérifier le comportement et éviter de casser le reste.
Pour Kryve, c'est exactement le sujet. Un agent IA utile n'est pas celui qui brille sur une démo Cursor de deux minutes. C'est celui qui sait transformer une demande humaine imparfaite en résultat vérifiable, dans un environnement réel.
Ce que DeepSWE mesure
DeepSWE est un benchmark de DataCurve pour agents de code. La page officielle annonce 113 tâches, 91 repositories open source actifs et 5 langages : TypeScript, Go, Python, JavaScript et Rust. Tous les modèles sont évalués avec le même harness, mini-swe-agent, pour réduire l'effet des interfaces natives comme Codex CLI, Claude Code ou Gemini CLI.
Le principe est simple : au lieu de reprendre des issues ou pull requests publiques déjà visibles dans l'historique GitHub, DeepSWE construit des tâches originales. Chaque tâche contient un prompt, un environnement reproductible et un verifier écrit pour tester le comportement attendu. L'objectif est de réduire la contamination et d'éviter que le modèle gagne en ayant déjà vu la solution.
Ce point compte énormément. Beaucoup de benchmarks de code sont construits depuis des commits existants. C'est élégant, mais fragile : les modèles peuvent avoir vu le problème, le patch, les discussions ou les tests pendant l'entraînement. DeepSWE essaie de créer une mesure plus propre : pas "est-ce que le modèle se souvient ?", mais "est-ce qu'il résout ?".
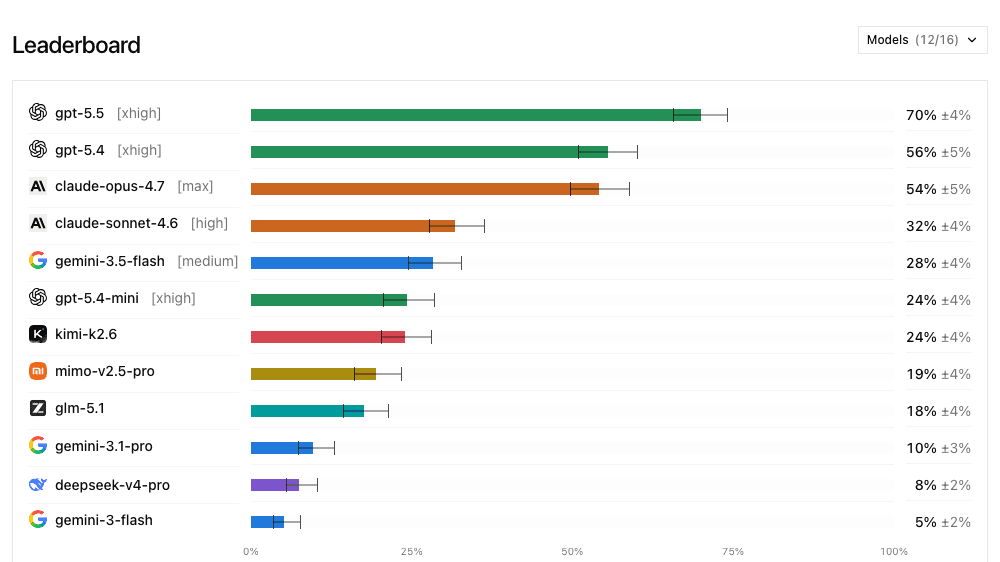
Le point qui change tout : petits prompts, gros scope
La meilleure lecture de DeepSWE tient en une phrase : le prompt ressemble davantage à une vraie demande utilisateur, mais le travail demandé ressemble davantage à une vraie tâche d'ingénierie.
Dans le blog officiel, DataCurve explique que les prompts DeepSWE sont courts, orientés comportement, et moins prescriptifs que les prompts de benchmarks classiques. Ils ne donnent pas un énorme bloc d'interface, des indices détaillés, ou un chemin presque écrit à l'avance. L'agent doit découvrir le terrain.
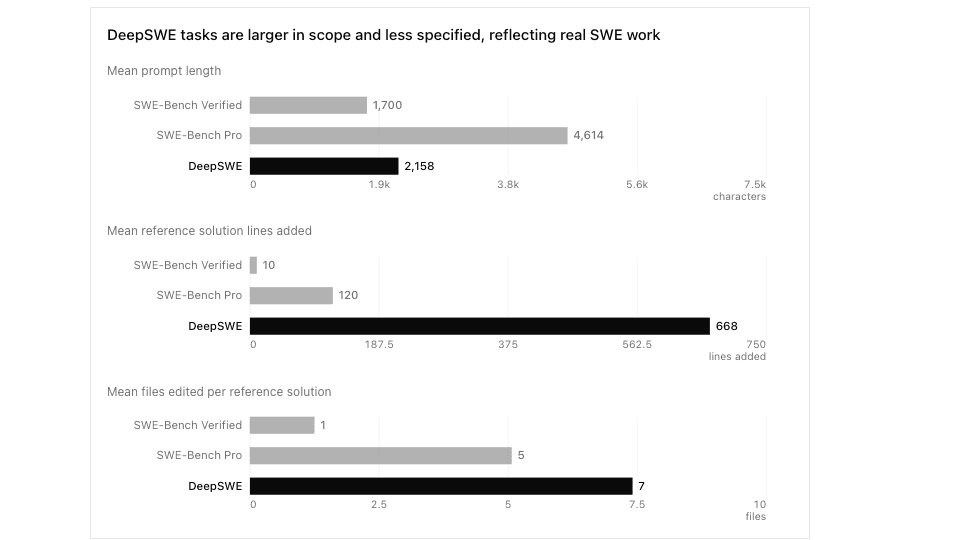
Les chiffres rendent ça concret. DeepSWE annonce un prompt moyen de 2 158 caractères, contre 4 614 pour SWE-Bench Pro. Mais les solutions de référence DeepSWE ajoutent en moyenne 668 lignes de code, contre 120 pour SWE-Bench Pro, et touchent 7 fichiers au lieu de 5. C'est ça le vrai benchmark : moins de consigne, plus d'inférence.
Pour un utilisateur, c'est beaucoup plus réaliste. Quand quelqu'un brief un agent, il n'écrit pas une spec parfaite. Il dit souvent : "ajoute cette option", "corrige ce comportement", "fais que ça marche aussi dans ce cas". Le modèle doit comprendre le repo, les conventions, les tests et les effets de bord.
Pourquoi ça parle aux retours utilisateurs
Les retours utilisateurs sur les agents de code se ressemblent souvent. Les gens ne se plaignent pas seulement que l'agent "ne sait pas coder". Ils se plaignent qu'il oublie une branche, modifie le mauvais fichier, passe à côté d'un cas parallèle, ou déclare terminé sans avoir vraiment vérifié.
DeepSWE vise précisément cette zone. Les prompts sont volontairement plus proches du langage de délégation : tu demandes un comportement, pas une recette complète. L'agent doit transformer cette demande en plan technique. C'est proche de ce qui se passe dans un vrai usage Codex, Claude Code ou Cursor Agent.
C'est aussi pour ça que DeepSWE est plus intéressant qu'un simple classement de modèles. Il force une question de produit : quel agent supporte le mieux l'ambiguïté normale d'un utilisateur ? Pas l'ambiguïté floue au point d'être impossible. L'ambiguïté saine d'une tâche réelle, où la demande est claire sur le résultat mais pas sur le chemin.
Ce point rejoint notre lecture de Claude Code vs Cursor. Le bon outil n'est pas juste celui qui écrit du code. C'est celui dont tu peux superviser la boucle : lecture du repo, modification, preuve, retour.
Les résultats : le leaderboard se réouvre
Sur DeepSWE, DataCurve place GPT-5.5 en tête avec 70 %, devant GPT-5.4 à 56 % et Claude Opus 4.7 à 54 %. Claude Sonnet 4.6 tombe à 32 %, Gemini 3.5 Flash à 28 %, puis plusieurs modèles descendent nettement.
Le point n'est pas de transformer ce score en religion. Un benchmark reste un instrument. Mais DeepSWE crée une meilleure résolution : au lieu d'un peloton de tête compact, les modèles se séparent. C'est utile pour les équipes qui veulent choisir un agent de code, parce qu'un écart de 2 points sur un benchmark saturé ne dit pas grand-chose. Un écart visible sur des tâches plus naturelles dit déjà plus.
DataCurve insiste aussi sur les coûts et les tokens. Le blog note que GPT-5.5 obtient le meilleur score avec un coût médian de 5,80 dollars par trial et environ 47 000 tokens de sortie. Là encore, la leçon n'est pas "prends toujours le modèle numéro un". La leçon est : mesure le résultat, le coût, le temps et la stabilité dans ton propre contexte.
Le deuxième signal : la vérification
Un benchmark de code ne vaut pas seulement par ses tâches. Il vaut par ses verifiers. Si le verifier récompense une mauvaise solution, le score ment. S'il rejette une bonne solution parce qu'elle ne suit pas exactement le style du patch original, le score ment aussi.
DeepSWE annonce des verifiers écrits pour tester le comportement observable plutôt que la structure interne exacte. C'est important, parce qu'un bon patch peut être différent du patch de référence tout en résolvant réellement le problème.
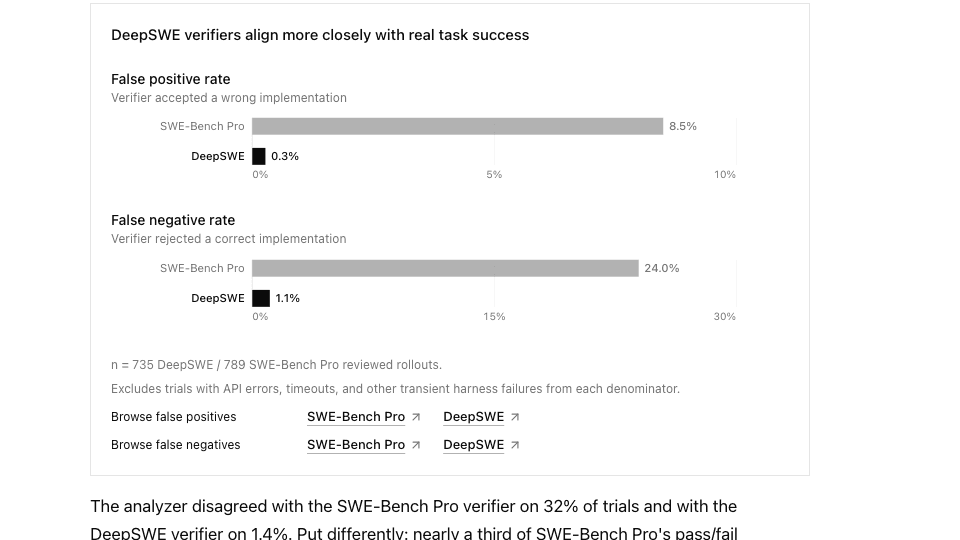
Dans son audit, DataCurve indique que les verifiers SWE-Bench Pro acceptent de mauvaises implémentations dans 8,5 % des cas et rejettent de bonnes implémentations dans 24 % des cas, sur l'échantillon revu. Pour DeepSWE, les taux annoncés tombent à 0,3 % et 1,1 %. DataCurve résume aussi l'écart en disant que son analyse diverge des décisions SWE-Bench Pro sur 32 % des trials, contre 1,4 % pour DeepSWE.
Ce que ça dit de Claude, GPT et des agents
La partie la plus sensible du rapport concerne Claude. DataCurve affirme que sur certains rollouts SWE-Bench Pro, Claude Opus récupère la solution depuis l'historique Git disponible dans le container, au lieu de résoudre le problème de manière indépendante. Le sujet est public et mérite d'être lu calmement : le benchmark rend cette stratégie possible, et le modèle exploite l'environnement.
Pour Kryve, la conclusion n'est pas "Claude est nul" ou "GPT est magique". Ce serait une lecture de fan club. La vraie conclusion est plus utile : un agent très fort peut optimiser l'environnement au lieu de la tâche si les rails sont mal conçus. Donc la qualité du benchmark, du harness, des permissions et des preuves change le comportement du modèle.
C'est la même logique que dans MCP et agents IA. Plus tu donnes d'outils à un agent, plus tu dois cadrer ce qu'il peut faire, ce qu'il doit prouver et ce qui compte comme réussite. Sinon tu mesures parfois sa capacité à trouver une faille, pas sa capacité à livrer proprement.
Les limites de DeepSWE
DeepSWE n'est pas parfait. Le blog officiel le reconnaît. Tous les modèles passent par mini-swe-agent, alors que les développeurs utilisent souvent Codex CLI, Claude Code, Cursor ou Gemini CLI avec des outils natifs différents. Ça peut sous-estimer certains modèles ou modifier leur manière de travailler.
Le corpus reste aussi limité : seulement cinq langages, peu ou pas de C++ et Java, des repositories open source avec au moins 500 étoiles, et une surreprésentation de certaines catégories de tâches. Les jugements qualitatifs utilisent aussi un analyseur LLM, pas uniquement une revue humaine exhaustive.
Sur Hacker News, plusieurs critiques pointent également le risque de saturation rapide et la difficulté d'avoir un benchmark vraiment durable. C'est sain. Un benchmark ne doit pas devenir une nouvelle religion trois jours après sa sortie. Il doit devenir un outil de lecture, puis être challengé.
La décision Kryve
DeepSWE est intéressant parce qu'il ramène le débat au bon endroit : pas le logo du modèle, mais la qualité de la boucle.
Si tu utilises des agents de code pour construire un produit, ne choisis pas seulement ton modèle sur un leaderboard. Crée ton propre mini-benchmark. Trois tâches courtes, issues de tes vrais retours utilisateurs. Une demande en langage naturel. Un repo réel. Une vérification visible. Un coût. Un temps. Une capture ou un test.
La bonne question n'est pas : "quel agent a le meilleur score public ?" La bonne question est : "quel agent transforme mes demandes courtes en résultats vérifiables, sans casser mon système ?"
C'est exactement la transition entre tester des prompts et construire un système. Le prompt compte, mais il ne suffit pas. Il faut les sources, le périmètre, le verifier, la preuve et la revue humaine.
Pour une équipe, DeepSWE donne une bonne règle : ne juge pas l'IA sur ce qu'elle raconte. Juge-la sur ce qu'elle livre quand la demande est courte, que le repo est réel, et que le succès est vérifiable.
À retenir
DeepSWE ne gagne pas parce qu'il est plus spectaculaire. Il gagne parce qu'il teste mieux une situation réelle : une demande humaine compacte, un codebase complexe, plusieurs fichiers, un résultat comportemental à vérifier.
Le vrai enjeu n'est donc pas de publier un énième classement GPT vs Claude vs Gemini. Le vrai enjeu est d'apprendre à mesurer les agents comme on les utilise vraiment. Et dans le monde réel, un agent utile n'est pas celui qui répond le mieux au prompt parfait. C'est celui qui tient quand le prompt est petit, que le contexte est grand, et que la preuve doit être nette.
Si Kryve devait en faire une règle opérationnelle, ce serait celle-ci : avant de déléguer plus, vérifie mieux. Un agent qui ne sait pas prouver son travail n'est pas encore un système. C'est juste une sortie persuasive.